UPDATE: June 26, 2020
The Orange County Health Care Agency changed their user interface in which they report the number
of cases for each city amongest other changes. It is much more modern with more types of insight.
One of the nice additions is the reporting of zip-codes that contain the accumulated number of
cases in the county. Unfortunately, this new Website still does not provide a history of number
of cases for zip-codes or city. I have refactored my code capture the new layout for daily cases
in the city as well as the new zip-code data.
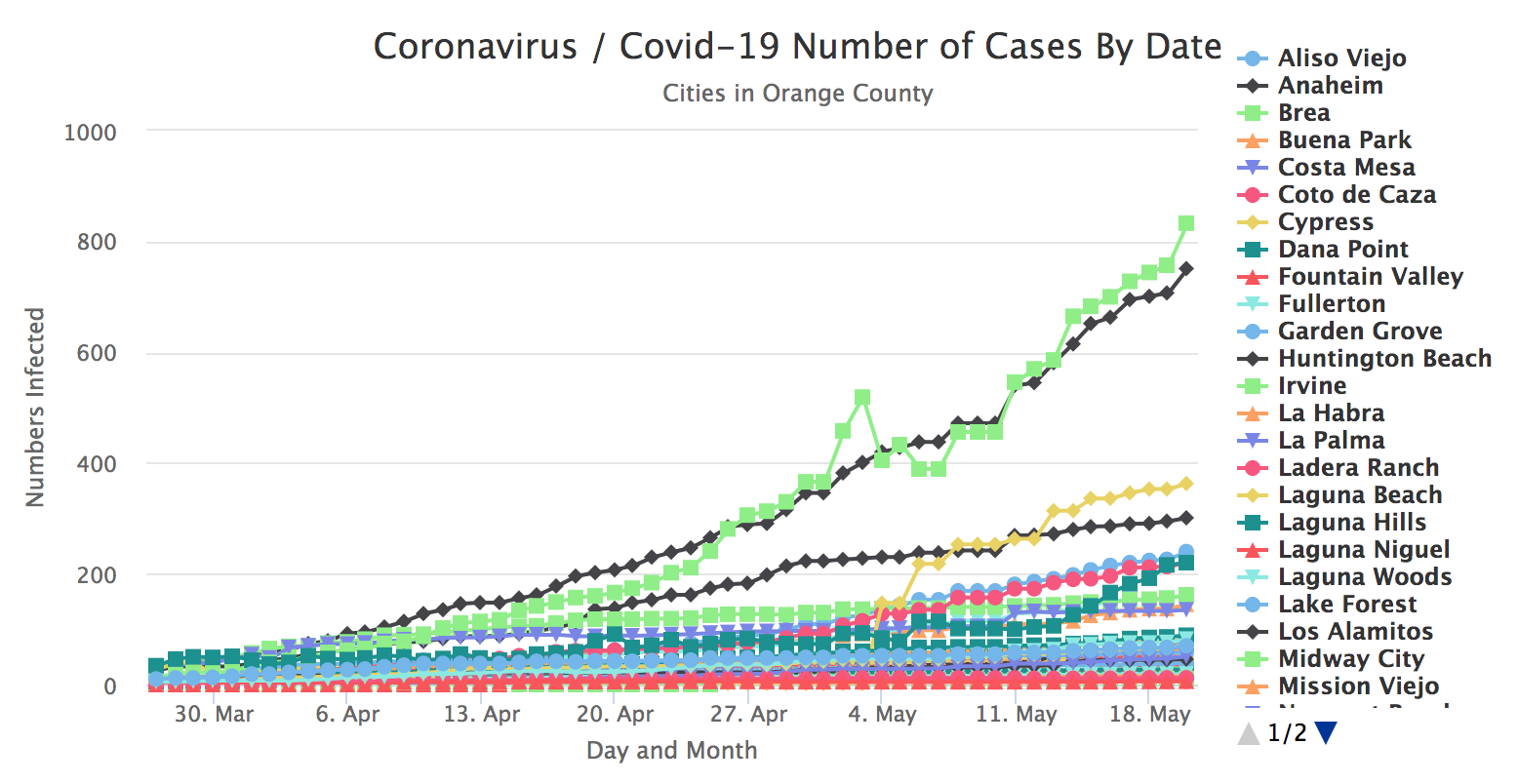
I have a backlog of COVID-19 data I kept track of since late March 2020. This data was manually pulled from a reliable source which contained the numbers of infected from the coronavirus by city in Orange County, California. Initially, I manually created charts from a spreadsheet and sent these charts to my friends and family on a regular basis. The data source only reported the total number of cases each day. This is unfortunate because it doesn't show the rate of growth in any way.
Months later, I was introduced to Highcharts and decided to look up the service. As anyone would expect of me, I decided to test Highcharts and saw that although relatively simple it is to use Highcharts, it was very powerful.
I decided to create essentially two applications. First, collect daily data from a source and append this new data to the data I already had. Second, create a User Interface to connect to this data and output a chart using Highcharts. Since this is now available to the world, anyone can visit this Website and see the chart, updated automatically at 6 PM Pacific Time.